英伟达祭出王炸 黄仁勋高调宣布:GH200超级芯片来袭!
英伟达的产品发布都打有深深的时代烙印。5年前,英伟达通过将人工智能和实时光线追踪技术引入GPU,5年后的今天,当人工智能的迅猛发展对芯片制造商提出更高的算力要求之时,英伟达又再次“提刀来见”
当地时间8月8日,英伟达CEO黄仁勋再次登陆计算机图形专业会议SIGGRAPH,并发布一系列产品,其中就包括了被称为GPU王炸的GH200 Grace Hopper超级芯片平台。

英伟达的产品发布都打有深深的时代烙印。5年前,英伟达通过将人工智能和实时光线追踪技术引入GPU,重新定义了计算机图形学。随之而来的则是集成了8个GPU并拥有1万亿个晶体管的NVIDIA HGX H100。
5年后的今天,当人工智能的迅猛发展对芯片制造商提出更高的算力要求之时,英伟达又再次“提刀来见”——GH200专门为加速计算和生成人工智能时代而打造,目标为处理世界上最复杂的生成式人工智能工作负载。
不仅面向算力支持的超级芯片,本次,英伟达围绕生成式AI的全生态发布了一系列更新,强势宣布本家产品矩阵即为当前人工智能训练的最强引擎。
GH200&NVIDIA NVLink™服务器
毫无疑问,本次英伟达发布的重头戏就是GH200。本次,英伟达为这款全称为Grace Hopper的超级芯片直接配上了全球首款HBM3e 处理器。据了解,这款全新的HBM3e内存要比当前的HBM3整整快了50%,配合10TB/sec的组合带宽,使得新平台可以运行比上一版本大3.5倍的模型。

这还不算完,作为英伟达本次推出的“王炸芯片”,GH200将基于 Arm 的 Nvidia Grace CPU 与 Hopper GPU 架构做了有效整合,使得GH200的GPU可以直接对标目前AI芯片天花板级别的H100。
不同的是,H100的内存为80GB,而新款GH200的内存将高达141GB,并可以和72核的ARM中央处理器进行配对。配置优化后,不仅性能大幅上升,GH200还可以执行AI推理功能,从而有效地为 ChatGPT 等生成式 AI 应用程序提供支持。
基于其强大的性能,英伟达直接在GH200的基础上进行了拓展,发布了NVIDIA NVLink™服务器对该芯片扩容。NVIDIA NVLink™将允许Grace Hopper超级芯片可以与其他超级芯片连接组合,这一技术方案为GPU提供了完全访问CPU内存的途径。

英伟达在Technical Blog中表示,目前正在开发一款新的双GH200基础NVIDIA MGX服务器系统,将集成两个下一代Grace Hopper超级芯片。在新的双GH200服务器中,系统内的CPU和GPU将通过完全一致的内存互连进行连接,这个超级GPU可以作为一个整体运行,提供144个Grace CPU核心、8千万亿次的计算性能以及282GB的HBM3e内存,从而能够适用于生成式AI的巨型模型。
目前,英伟达计划销售GH200的两种版本:一种是包含两个可供客户集成到系统中的芯片,另一种则是结合了两种 Grace Hopper 设计的完整服务器系统,预计将于明年二季度上市。
RTX矩阵& RTX Workstation
除了强大的Grace Hopper芯片,英伟达也有意将市场主流的生成式AI工作程序和自家产品绑定,一口气推出了三款新GPU:RTX 5000、RTX 4500和RTX 4000。
去年,英伟达推出的RTX 6000一经发布就成为了业界天花板,凭借48GB的显存,18176个CUDA核心,568个Tensor核心,142个RT核心,和高达960GB/s的带宽,在业内大杀特杀。
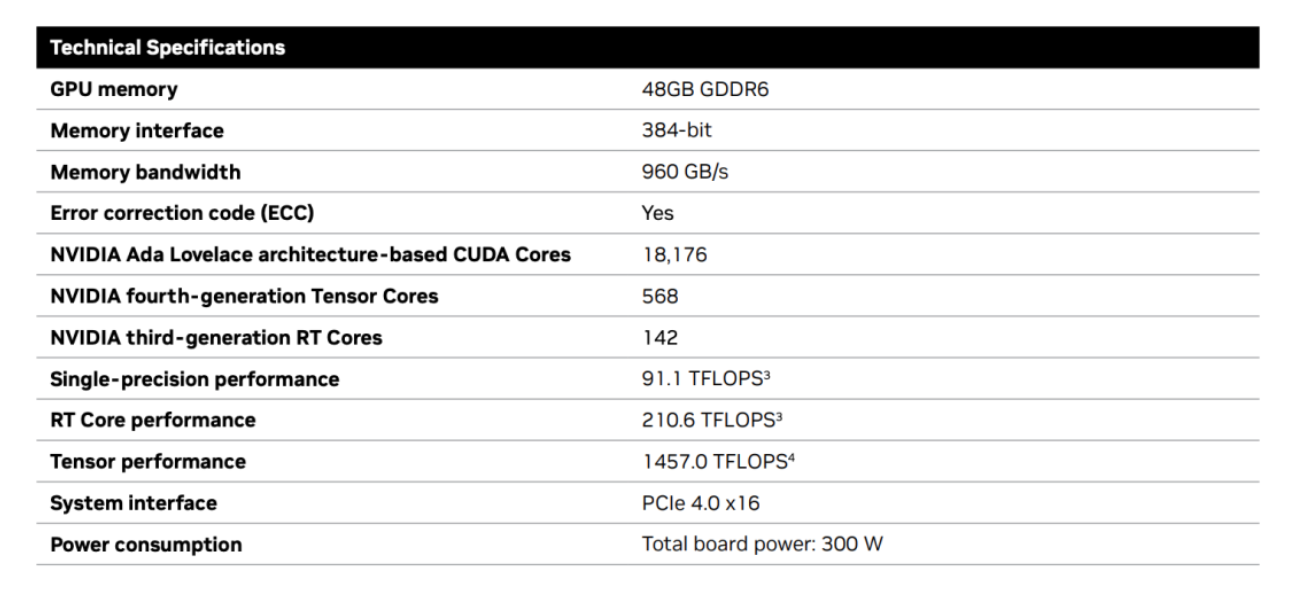
在天花板的激励下,本次英伟达推出的新产品配置也没有让大家失望:RTX 5000配备了32GB显存,12800个CUDA核心,400个Tensor核心,100个RT核心;RTX 4500配备了24GB显存,7680个CUDA核心,240个Tensor核心,60个RT核心;RTX 4000配备了20GB显存,6144个CUDA核心,192个Tensor核心,48个RT核心。
基于这三张GPU,面向企业客户,英伟达旨在为其提供最新的 AI图形和实时渲染技术,推出了了一套一站式解决方案 RTX Workstation。在这项方案中,RTX Workstation可以支持最多4张RTX 6000 GPU,使其在15小时内完成8.6亿token的GPT3-40B的微调,还能让Stable Diffusion XL每分钟生成40张图片,这个速度是原先4090的5倍。
AI Workbench
除了硬件,本次英伟达在软件的雕琢上也下了功夫。
在SIGGRAPH上,黄仁勋还推出了一个全新的AI服务平台:NVIDIA AI Workbench,以辅助用户开发和部署生成式AI模型,然后将其扩展到几乎任何数据中心、公共云或NVIDIA DGX™ 云。
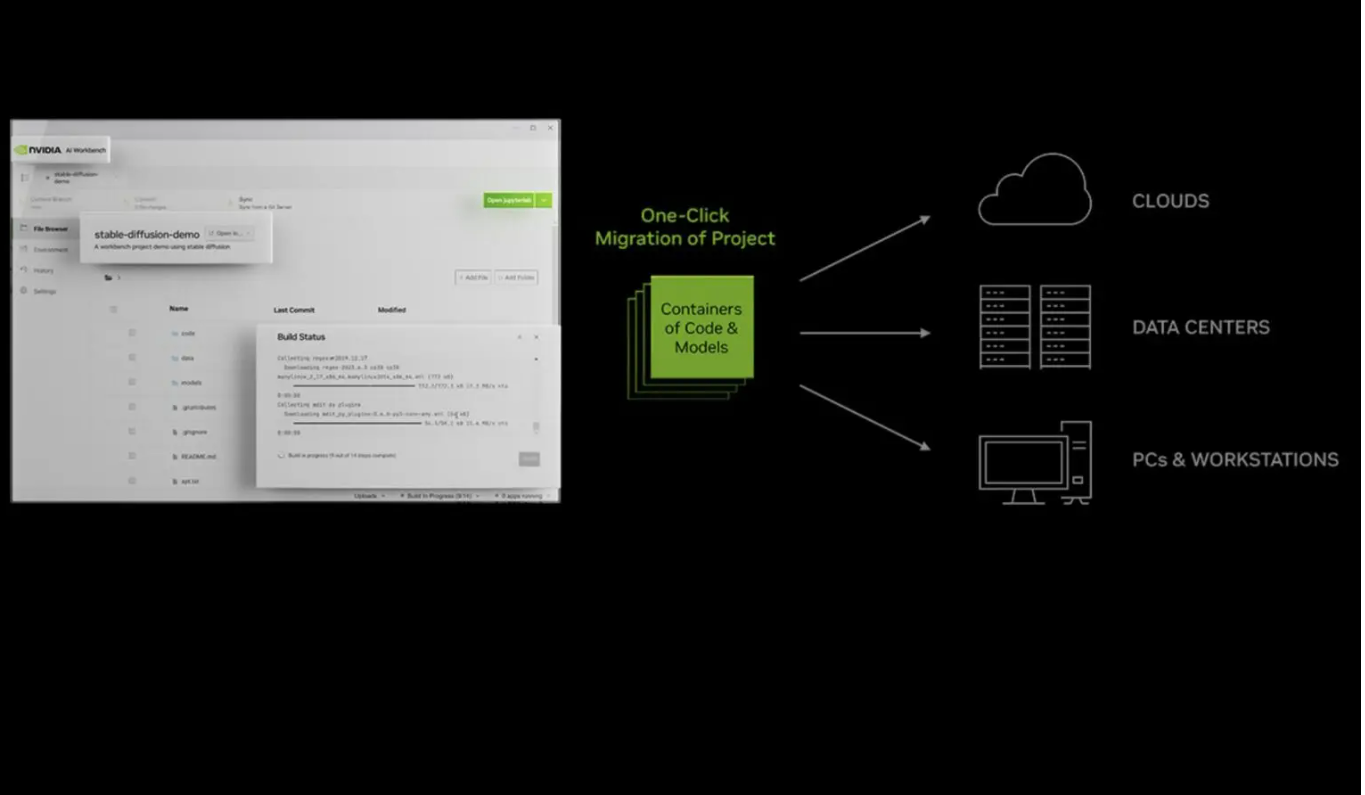
在英伟达的表述中,当前企业级AI的开发过程太过繁琐和复杂,不仅需要在多个库中寻找合适的框架和工具,当项目需要从一个基础设施迁移到另一个基础设施时,过程可能会变得更加具有挑战性。
于是,AI Workbench提供了一个简单的用户界面,开发人员能够将模型、框架、SDK 和库从开源资源整合到统一的工作区中,可以在本地计算机上运行并连接到 HuggingFace、Github以及其他流行的开源或商用 AI 代码存储库。也就是说,开发人员可以在一个界面上轻松访问大部分AI开发所需资源,不用打开不同的浏览器窗口。
英伟达表示,AI Workbench的优势包括:
- 易于使用:
- 集成AI开发工具和存储库:
- 增强协作:
- 访问加速计算资源:
英伟达称,目前戴尔、惠普、Lambda、联想等人工智能基础设施提供商已经采用了 AI Workbench服务,并看到了其提升最新一代多 GPU 能力的潜力。在实际用例中,Workbench 可以帮助用户从单台 PC 上的开发转向更大规模的环境,在所有软件都保持不变的情况下帮助项目投入生产。
·原创文章
免责声明:本文观点来自原作者,不代表Hawk Insight的观点和立场。文章内容仅供参考、交流、学习,不构成投资建议。如涉及版权问题,请联系我们删除。











